IT-Beratung
Open Source Log Management
Betriebssysteme, Applikationen, Firewalls und Netzwerkkomponenten produzieren Logdaten. Selbst in einer kleinen bis mittelständischen Firma fallen einige Gigabyte täglich an. Interessante und wichtige Meldungen können in dieser großen Datenmenge jedoch schnell verloren gehen. Da die Anzahl der Logmeldungen schon von einfachen Systemen bei manueller Verarbeitung kaum überschaubar ist, ist hier maschinelle Unterstützung fast zwingend notwendig. Die zentrale Sammlung der Logdaten und damit die Möglichkeit der Datensuche auf einer Oberfläche, vereinfacht die Fehleranalyse enorm. Fehlermeldungen können automatisch erkannt und Alarme gezielt ausgelöst werden.
Unter Log Management versteht man das Definieren, Empfangen, Auswerten, Speichern und Löschen von Protokolldaten, die während des Betriebs erzeugt werden. Es fasst die Protokolle aller IT-Systeme eines Computernetzwerks an einer zentralen Stelle zusammen. Logdaten sind Protokolle über Änderungen und den Betrieb von Computersystemen.
Log Management analysiert Ihren Datenberg und sorgt dafür, dass unternehmensrelevante Meldungen an die richtige Stelle weitergeleitet werden. Zusätzlich können die Daten durch den Einsatz eines Log Management Tools korreliert werden, was wichtige Zusammenhänge Ihrer Daten erkennen lässt. Dieser holistische Ansatz ist insbesondere im Sicherheitskontext von Bedeutung.
Log Management erlaubt die komplexere Analyse der Daten über die Zeit. Gerade bei Sicherheitsvorfällen ist ein Angriff häufig nicht an einer einzelnen Logmeldung zu erkennen. Vielmehr sind erst durch eine statistische Auswertung Muster zu erkennen, die den Angriff sichtbar machen - und das ohne zusätzliche Last auf den Systemen zu erzeugen, da Logdaten in der Regel automatisch erzeugt werden.
Statistiken und Reports über die gesammelten Daten erlauben zudem das Capacity Planning Ihrer IT-Infrastruktur und im Personalwesen.
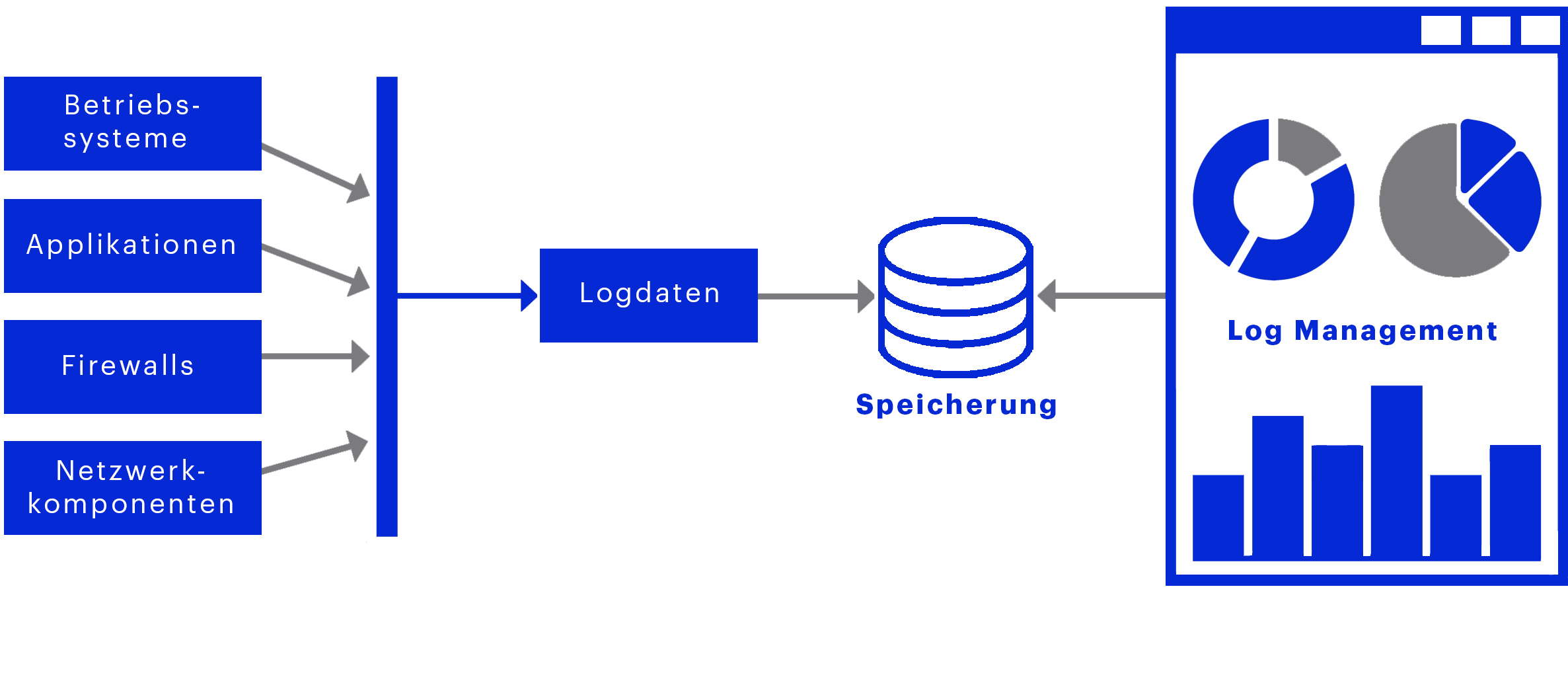
Abb. 1 Darstellung Log Management
IT-Performance Überwachung durch Log Management
Log Management unterstützt Unternehmen nicht nur bei der Einhaltung von Compliance Vorgaben. Es sorgt auch dafür, IT besser steuerbar zu machen, vorausschauend zu kontrollieren und ein kontinuierliches Qualitätsmanagement zu sichern. Wichtige Kriterien dabei sind:
- Die Log Management Lösung muss unbegrenzt erweiterbar sein
- Verarbeitung von mehreren Terabytes an Logs dürfen zu keiner Überlastung führen
- Auch Cloud-Umgebungen sollten im Idealfall abdeckt sein
- Auswertungen der Logs müssen die Richtlinien des Datenschutzes berücksichtigen
- Im Spezialfall sollten sämtliche Logdaten revisionssicher erfasst werden
Open Source-Lösung der matrix - zum Test als Festpreis
Log Management sorgt für Zeit- und Kostenersparnisse durch vereinfachte Fehleranalyse und kann zudem komplexere Zusammenhänge aus den bereits vorhandenen Daten erkennen. Ob frühzeitige Fehlererkennung, Sammlung von Performancedaten, Erkennen von Sicherheitsvorfällen oder Reporterstellung zum Stand Ihrer IT – testen Sie jetzt die Log Management Lösung der matrix zum Festpreis.
Als Proof of Concept (POC) baut die matrix eine Log Management Plattform auf und integriert bis zu zehn Standard Datenquellen. Die matrix stellt dafür die Appliance (Hardware oder virtuell) zur Verfügung. Nach einer Baselining Phase, in der die Normalwerte diverser KPIs aus den Logdaten ermittelt werden, definiert das matrix Team gemeinsam mit den Kunden Alarme. Nach einer mehrwöchigen Testphase kann die matrix Log Management Lösung weiterhin genutzt oder zurückgebaut werden.
Log Management der matrix - in 5 Schritten zum Erfolg

Bei Weiterbetrieb der Log Management Lösung fallen monatlich Wartungskosten und evtl. Kosten für die Integration weiterer Datenquellen oder die Erstellung weiterer Reports / Alarme an, die kundenindividuell im Rahmen des POCs gemeinsam besprochen werden können.

Log Management vs. SEM, SIEM & Co.
- Klärung der Begriffe -
Es gibt viele Möglichkeiten, sicherheitsrelevante Vorfälle zu identifizieren und respektive zu verhindern sowie die Leistung von Systemen und Mitarbeitern zu steigern.
Haben Sie Fragen?
Wir helfen Ihnen gerne weiter!
